An advantage based policy transfer algorithm for reinforcement learning with metrics of transferability
- Md Ferdous Alam The Ohio State University
- Parinaz Naghizadeh University of California, San Diego
- David Hoelzle The Ohio State University
SAC policy Apt-RL policy
Abstract
Reinforcement learning (RL) can enable sequential decision-making in complex and high- dimensional environments if the acquisition of a new state-action pair is efficient, i.e., when interaction with the environment is inexpensive. However, there are a myriad of real-world applications in which a high number of interactions are infeasible. In these environments, transfer RL algorithms, which can be used for the transfer of knowledge from one or multiple source environments to a target environment, have been shown to increase learning speed and improve initial and asymptotic performance. However, most existing transfer RL algo- rithms are on-policy and sample inefficient, and often require heuristic choices in algorithm design. This paper proposes an off-policy Advantage-based Policy Transfer algorithm, APT- RL, for fixed domain environments. Its novelty is in using the popular notion of “advantage” as a regularizer, to weigh the knowledge that should be transferred from the source, relative to new knowledge learned in the target, removing the need for heuristic choices. Further, we propose a new transfer performance metric to evaluate the performance of our algorithm and unify existing transfer RL frameworks. Finally, we present a scalable, theoretically-backed task similarity measurement algorithm to illustrate the alignments between our proposed transferability metric and similarities between source and target environments. Numerical experiments on three continuous control benchmark tasks demonstrate that APT-RL out- performs existing transfer RL algorithms on most tasks, and is 10% to 75% more sample efficient than learning from scratch.
Experiments
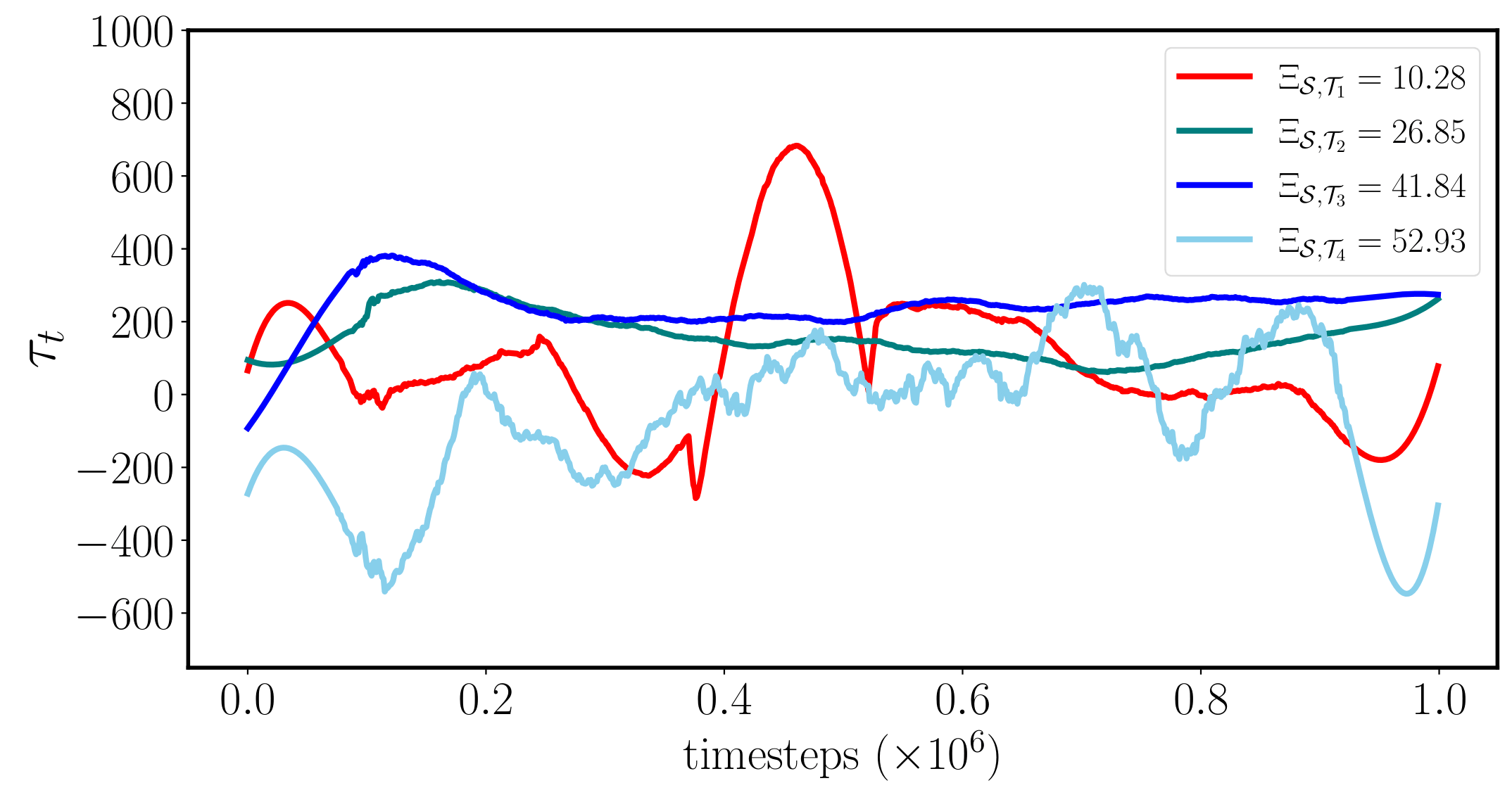
Pendulum





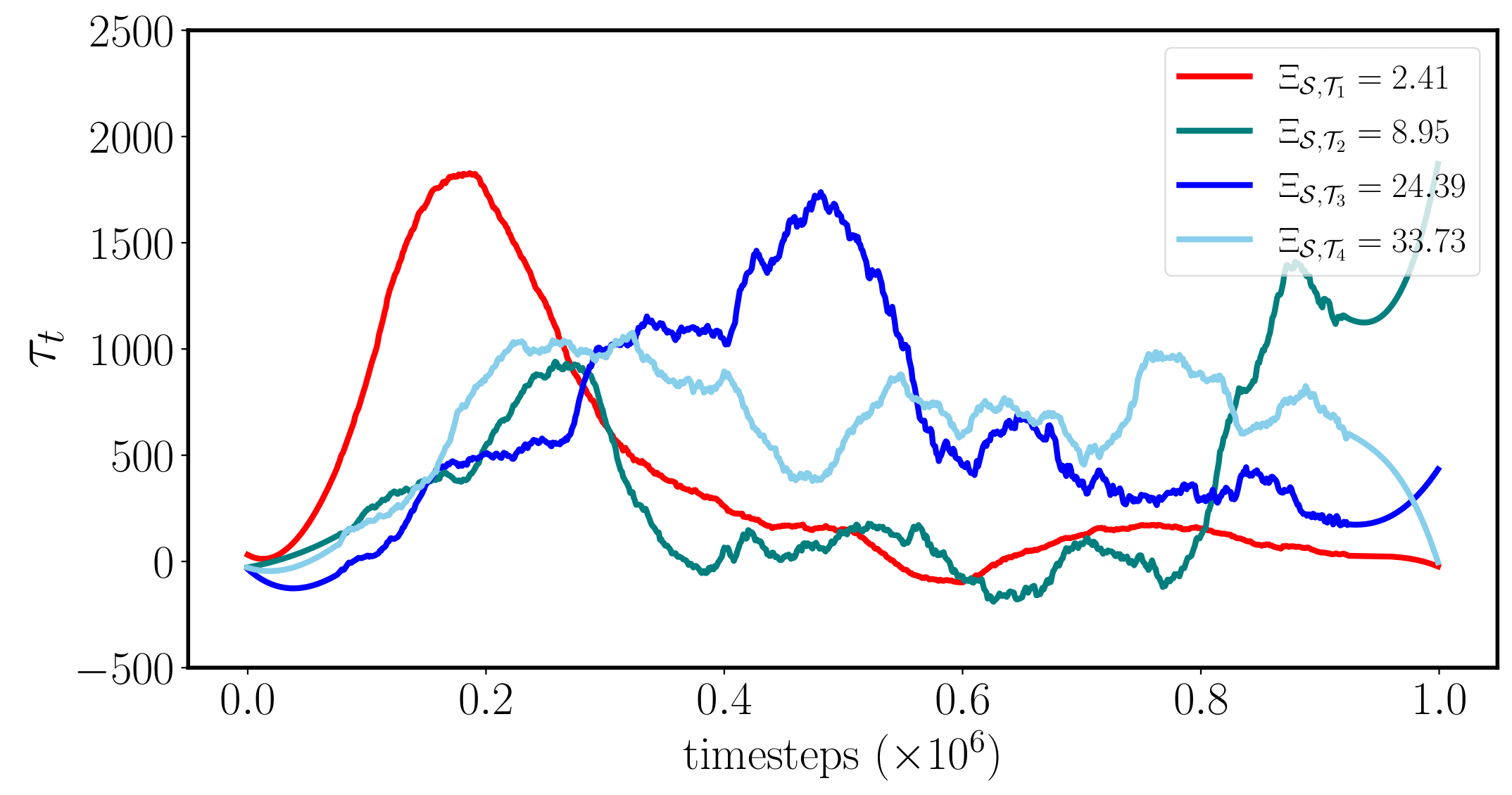
Half-Cheetah-v3





Ant-v3





Results
Task similarity
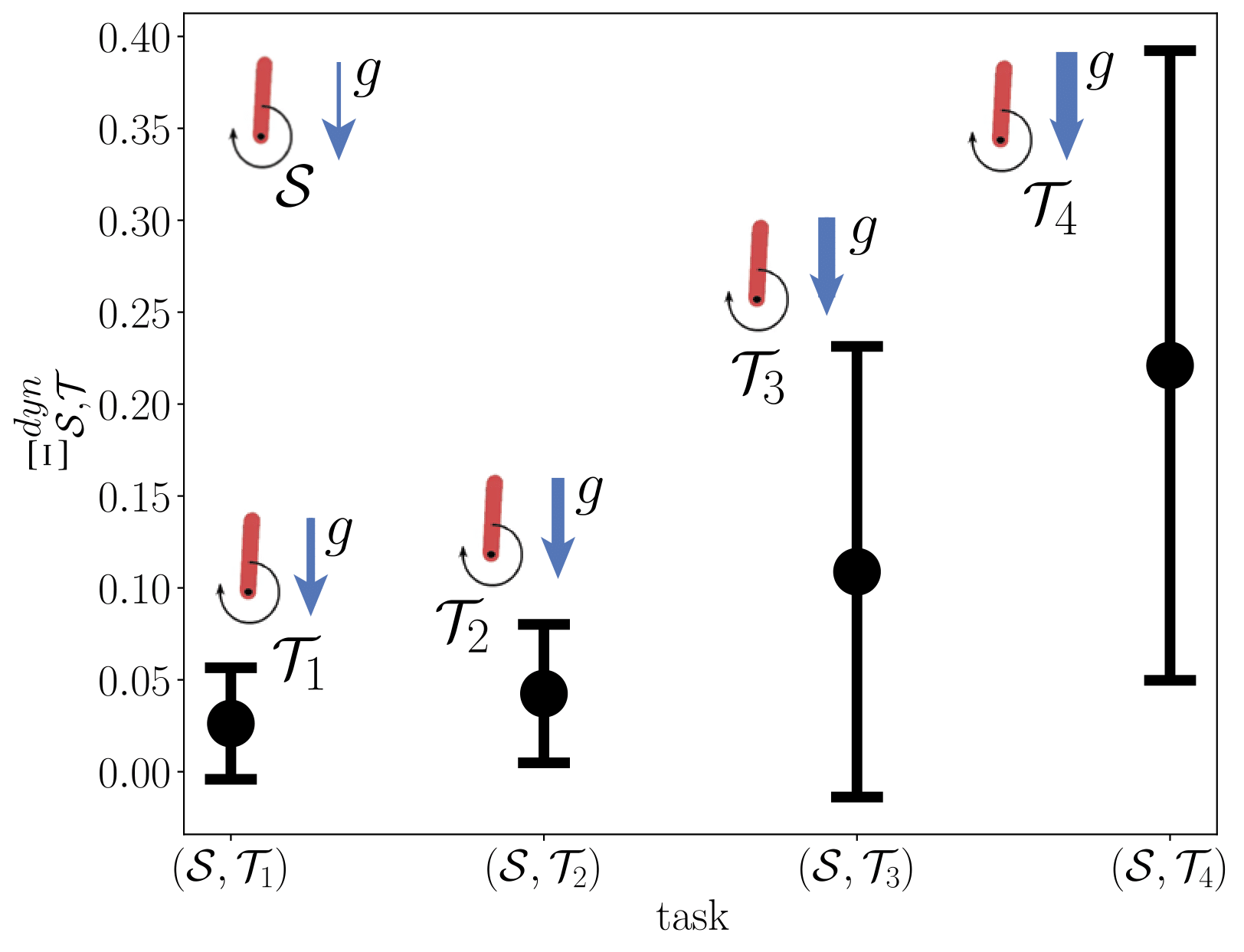
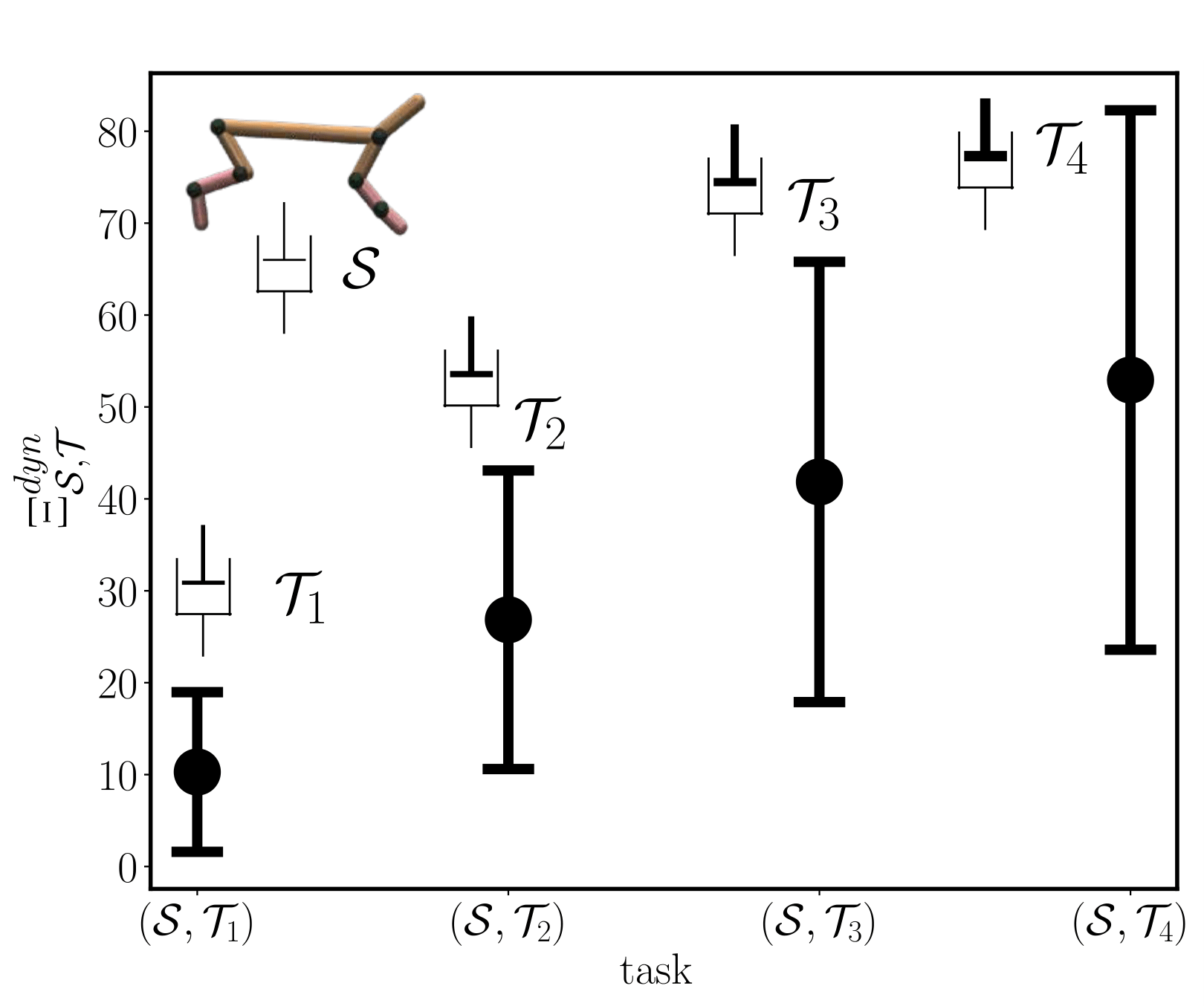
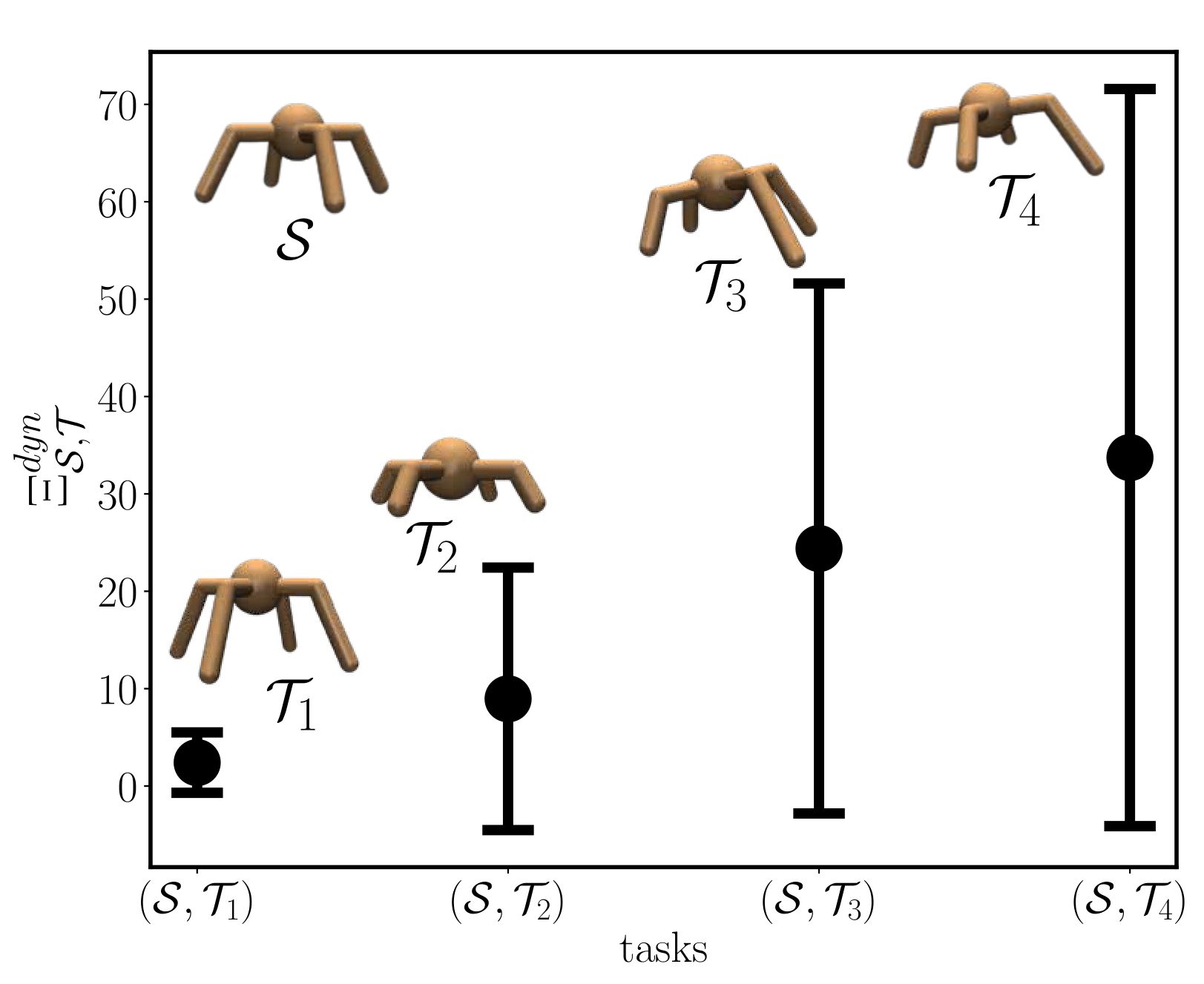
Transferability